GIS云套件
开启分布式分析服务
开启分布式分析服务前,需先添加计算资源,请参照GIS云套件->计算资源池中的介绍。添加后请参考以下步骤开启分布式分析服务:
- 点击页面左侧导航栏服务管理->分布式分析服务;
-
点击开启,如下图所示:
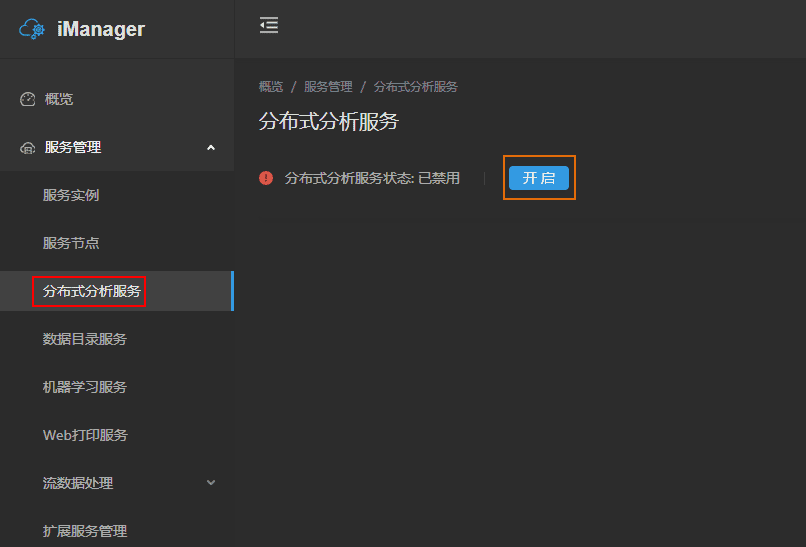
-
选择计算资源,如下图所示:
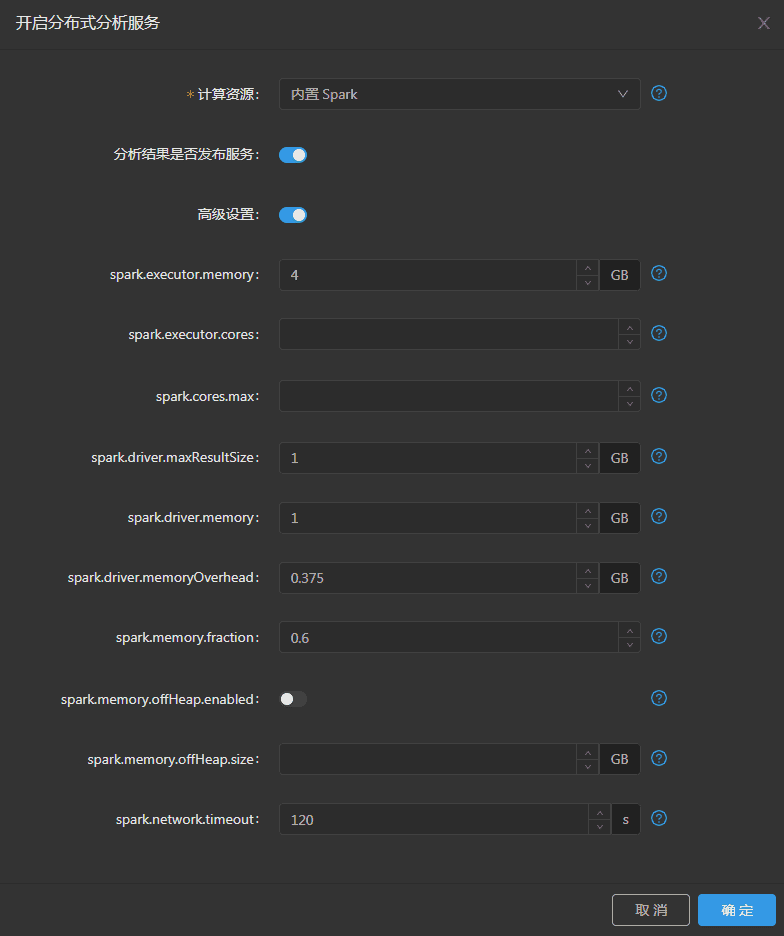
- 分析结果是否发布服务:开启后分析结果自动发布为服务。
如果使用内置Spark,则在高级设置中可设置以下参数:
- spark.executor.memory:每个执行进程的内存大小。
- spark.exector.cores:每个执行进程的CPU内核数。
- spark.cores.max:分布式分析服务使用CPU内核上限。
- spark.driver.maxResultSize:spark操作的所有分区的序列化结果上限(如:collect行动算子)。设为0则无限制。
- spark.driver.memory:分布式分析服务内存大小。
- spark.driver.memoryOverhead:分布式分析服务的堆外内存。
- spark.memory.fraction:执行任务所占内存与总内存比例。数值越低,内存溢出和缓存回收的频率越高。
- spark.memory.offHeap.enabled:开启后允许spark使用堆外内存进行操作。
- spark.memory.offHeap.size:堆外分配的内存量,需开启spark.driver.offHeap.enabled。
- spark.network.timeout:网络交互默认超时时长。
-
开启成功后会得到下图右上角所示的提示:
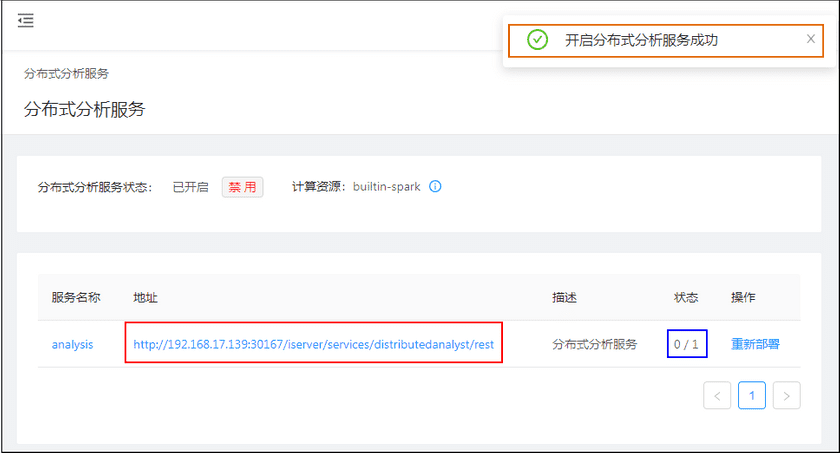
- 等待上图状态变为1/1时,则分布式分析服务准备就绪;
-
点击地址处的链接进入并使用分布式分析服务。
备注:
分布式分析服务的使用方法请参见SuperMap iServer帮助文档(使用 iServer > 使用分布式分析服务)。